Begreppet representativitet finns ofta istatistiska rapporter och vid beredning av tal och rapporter. Kanske utan det är det svårt att föreställa sig någon form av presentation av information för granskning.
Representativitet - vad är det?

Representativitet återspeglar i vilken utsträckning de valda objekten eller delarna överensstämmer med innehållet och betydelsen av datauppsättningen från vilken de valdes.
Andra definitioner
Begreppet representativitet kan avslöjas iolika sammanhang. Men i sin mening är representativitet korrespondensen mellan funktionerna och egenskaperna hos utvalda enheter från den allmänna befolkningen, som exakt speglar egenskaperna hos hela den allmänna databasen som helhet.

Informationens representativitet definieras också som förmågan hos samplade data att representera parametrarna och egenskaperna hos befolkningen som är viktiga ur den forskning som bedrivs.
Representativt urval
Provtagningsprincipen ärval av de viktigaste och exakt återspeglar egenskaperna hos den allmänna befolkningen av data. För detta används olika metoder som gör det möjligt att få exakta resultat och en allmän uppfattning om den allmänna befolkningen, med endast provmaterial som beskriver kvaliteten på all data.
Därför är det inte nödvändigt att studera helamaterial, men det räcker med att överväga selektiv representativitet. Vad är det? Detta är ett urval av individuella data för att få en uppfattning om den totala massan av information.

De utmärks, beroende på metod, somsannolikhet och osannolikt. Probabilistic är ett urval som görs genom att beräkna de viktigaste och mest intressanta uppgifterna, som i framtiden är representanter för den allmänna befolkningen. Detta är ett avsiktligt val eller ett slumpmässigt urval, dock motiverat av dess innehåll.
Osannolikt är en av sorternastickprov, sammanställt enligt principen för ett vanligt lotteri. I det här fallet tas inte hänsyn till den som gör ett sådant prov. Endast en blindlott används.
Sannolikhetsprovtagning
Sannolikhetsprover kan också delas in i flera typer:
- En av de enklaste och mest begripliga principerna ärurepresentativt urval. Till exempel används denna metod ofta vid sociala undersökningar. Samtidigt väljs undersökningsdeltagare inte ut från mängden för några specifika kriterier, och information erhålls från de första 50 personerna som deltog i den.
- Avsiktliga prover skiljer sig åt genom att de har ett antal krav och villkor för urval, men ändå förlita sig på tillfälligheter, utan att sträva efter målet att uppnå god statistik.
- Kvotprovtagning är en annanvariationer i osannolikhetsprovet, som ofta används för att utforska stora datamängder. Många villkor och normer används för det. Objekt väljs ut som måste motsvara dem. Det vill säga med hjälp av exemplet på en social undersökning kan man anta att 100 personer kommer att intervjuas, men endast ett visst antal personer som kommer att uppfylla de fastställda kraven kommer att beaktas vid sammanställning av en statistisk rapport.

Sannolikhetsprover
För sannolikhetsprover beräknas serienparametrar som objekten i urvalet kommer att motsvara, och bland dem på olika sätt, kan exakt de fakta och data väljas som presenteras som representativiteten för provdata. Sådana metoder för att beräkna erforderlig data kan vara:
- Enkelt slumpmässigt urval.Det består i det faktum att bland det valda segmentet väljs den nödvändiga datamängden med en helt slumpmässig lotterimetod, som kommer att vara ett representativt urval.
- Systematisk och slumpmässig provtagning germöjligheten att komponera ett system för beräkning av nödvändig data baserat på ett slumpmässigt valt segment. Om det första slumpmässiga talet som anger sekvensnumret för de data som valts från den totala befolkningen är 5, kan efterföljande data som ska väljas till exempel vara 15, 25, 35 och så vidare. Detta exempel förklarar tydligt att även ett slumpmässigt val kan baseras på systematiska beräkningar av erforderliga inmatningsdata.
Exempel på konsumenter
Meningsfull provtagning är såär att överväga varje enskilt segment, och baserat på dess bedömning sammanställs en uppsättning som återspeglar egenskaperna och egenskaperna hos den gemensamma databasen. Således samlas mer data in som uppfyller kraven för ett representativt urval. Det är lätt att välja ett antal alternativ som inte kommer att ingå i totalen, utan att förlora kvaliteten på den valda data som representerar den allmänna befolkningen. På detta sätt bestäms forskningsresultatens representativitet.
Provstorlek
Inte den sista frågan som ska lösas -det är urvalet för en representativ representation av befolkningen. Urvalet beror inte alltid på antalet källor i den allmänna befolkningen. Provpopulationens representativitet beror emellertid direkt på hur många segment resultatet slutligen ska delas upp i. Ju fler sådana segment det finns, desto mer data ingår i det resulterande urvalet. Om resultaten kräver allmän notering och inte kräver specificitet, blir följaktligen urvalet mindre, eftersom informationen utan att gå in på detaljer presenteras mer ytligt, vilket innebär att dess läsning blir allmän.

Begreppet fel i representativitet
Representativitetsfelet är specifiktskillnader mellan egenskaper hos den allmänna befolkningen och provdata. När man utför någon provstudie är det omöjligt att få absolut korrekta data, som i en fullständig studie av allmänna populationer och ett urval som endast representeras av en del av informationen och parametrarna, medan en mer detaljerad studie endast är möjlig när man studerar hela befolkningen . Därför är vissa fel och misstag oundvikliga.
Typer av fel
Det finns några fel som uppstår när ett representativt prov sammanställs:
- Systematisk.
- Random.
- Avsiktlig.
- Oavsiktlig.
- Standard.
- Begränsa.
Orsaken till att slumpmässiga fel uppträder kan vara den diskontinuerliga karaktären av studien av den allmänna befolkningen. Vanligtvis är det slumpmässiga felet av representativitet av mindre storlek och karaktär.
Systematiska fel uppstår under tiden när reglerna för val av data från den allmänna befolkningen bryts.

Det genomsnittliga felet är skillnaden mellan medelvärdetvärden för urvalet och huvudpopulationen. Det beror inte på antalet enheter i urvalet. Det är omvänt proportionellt mot provstorleken. Ju större volym, desto mindre värde för genomsnittsfelet.
Det marginella felet är det största möjligaskillnaden mellan medelvärdet av provet och den totala populationen. Ett sådant fel kännetecknas som maximalt av troliga fel under de givna förhållandena för deras inträffande.
Avsiktliga och oavsiktliga fel i representativiteten
Databiasfel kan vara avsiktligt eller oavsiktligt.
Sedan orsakerna till att avsiktliga fel uppstårär en trendbaserad metod för datainsamling. Oavsiktliga fel uppstår även vid förberedelsestadiet av selektiv observation, bildandet av ett representativt prov. För att undvika sådana fel är det nödvändigt att skapa en bra samplingsram för listorna över provtagningsenheter. Det bör vara helt förenligt med urvalets mål, vara tillförlitligt och täcka alla aspekter av studien.
Validitet, tillförlitlighet, representativitet. Felberäkning
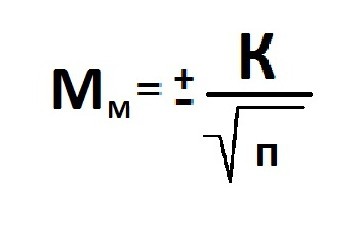
Beräkning av representativitetsfelet (Mm) för det aritmetiska medelvärdet (M).
Standardavvikelse: provstorlek (> 30).
Representativt fel (Мр) och relativt värde (Р): provstorlek (n> 30).
Om det är nödvändigt att studera en population där urvalet är litet och är mindre än 30 enheter, kommer antalet observationer att minska med en enhet.
Felets storlek är direkt proportionell mot urvalsstorleken. Informationens representativitet och beräkningen av möjligheten att göra en korrekt prognos speglar ett visst värde på det marginella felet.

Representativa system
Inte bara för att utvärdera presentationen av informationett representativt prov används, men den person som tar emot informationen själv använder representativa system. Således bearbetar hjärnan en viss mängd information och skapar ett representativt urval av hela informationsflödet för att kvalitativt och snabbt utvärdera den tillhandahållna informationen och förstå essensen i frågan. Svara på frågan: "Representativitet - vad är det?" - på människans medvetenhets skala är det ganska enkelt. För detta använder hjärnan alla underordnade sinnesorgan, beroende på vilken typ av information som behöver isoleras från det allmänna flödet. Således görs en åtskillnad mellan:

- Ett visuellt representationssystem, därorganen för visuell uppfattning av ögat är inblandade. Människor som ofta använder detta system kallas visuals. Med hjälp av detta system bearbetar en person information som kommer i form av bilder.
- Auditivt representationssystem.Huvudorganet som används är hörsel. Information som tillhandahålls i form av ljudfiler eller tal behandlas av just detta system. Människor som uppfattar information bättre i örat kallas audials.
- Det kinestetiska representationssystemet är behandlingen av informationsflöde genom att uppfatta det genom lukt- och taktila kanaler.
- Det digitala representationssystemet används tillsammans med andra som ett sätt att få information utifrån. Detta är en subjektiv-logisk uppfattning och förståelse av de erhållna uppgifterna.

Så, vad är representativitet?Ett enkelt urval från en uppsättning eller ett integrerat förfarande vid informationsbehandling? Vi kan entydigt säga att representativitet i stor utsträckning avgör vår uppfattning av dataströmmar, vilket hjälper till att isolera de viktigaste och viktigaste från det.








