Reprezentativitātes jēdziens bieži sastopamsstatistikas ziņojumos un runu un ziņojumu sagatavošanā. Varbūt bez tā ir grūti iedomāties jebkāda veida informācijas sniegšanu pārskatīšanai.
Pārstāvība - kas tas ir?

Pārstāvība atspoguļo to, cik lielā mērā atlasītie objekti vai daļas atbilst tās datu kopas saturam un nozīmei, no kuras tie tika atlasīti.
Citas definīcijas
Reprezentativitātes jēdzienu var atklātdažādos kontekstos. Bet savā nozīmē reprezentativitāte ir izvēlēto vienību pazīmju un īpašību atbilstība no vispārējās populācijas, kas precīzi atspoguļo visas vispārējās datu bāzes īpašības kopumā.

Tāpat informācijas reprezentativitāte tiek definēta kā izlasē iekļauto datu spēja atspoguļot populācijas parametrus un īpašības, kas ir svarīgi no veicamā pētījuma viedokļa.
Reprezentatīvs paraugs
Izlases princips irvissvarīgāko un precīzāk atspoguļojošo datu kopas īpašību atlase. Tam tiek izmantotas dažādas metodes, kas ļauj iegūt precīzus rezultātus un vispārēju priekšstatu par vispārējo populāciju, izmantojot tikai materiālu paraugus, kas raksturo visu datu kvalitāti.
Tādējādi nav nepieciešams izpētīt visumateriāls, bet pietiek apsvērt selektīvu reprezentativitāti. Kas tas ir? Šī ir atsevišķu datu atlase, lai iegūtu priekšstatu par kopējo informācijas masu.

Tos izšķir atkarībā no metodes, kāvarbūtēja un neticama. Varbūtība ir izlase, kas tiek veikta, aprēķinot vissvarīgākos un interesantākos datus, kas nākotnē ir vispārējās populācijas pārstāvji. Tomēr tā ir apzināta izvēle vai izlases veida izlase, ko pamato tās saturs.
Neticama ir viena no šķirnēmizlases veida paraugu ņemšana, kas sastādīta pēc kārtējās loterijas principa. Šajā gadījumā netiek ņemts vērā tās personas viedoklis, kura veido šādu paraugu. Tiek izmantota tikai aklā partija.
Varbūtības atlase
Varbūtības paraugus var arī iedalīt vairākos veidos:
- Viens no vienkāršākajiem un saprotamākajiem principiem irnepārstāvoša izlase. Piemēram, šo metodi bieži izmanto, veicot sociālās aptaujas. Tajā pašā laikā aptaujas dalībnieki netiek izvēlēti no pūļa pēc kādiem konkrētiem kritērijiem, un informācija tiek iegūta no pirmajiem 50 cilvēkiem, kas tajā piedalījās.
- Tīšas izlases atšķiras ar to, ka tām ir vairākas prasības un nosacījumi izvēlei, taču tās joprojām paļaujas uz sakritību, nevis tiecoties sasniegt labu statistiku.
- Kvotu atlase ir vēl vienaneticamības izlases variācijas, ko bieži izmanto lielu datu kopu izpētei. Tam tiek izmantoti daudzi nosacījumi un normas. Tiek atlasīti objekti, kuriem tiem jāatbilst. Tas ir, izmantojot sociālās aptaujas piemēru, var pieņemt, ka tiks intervēti 100 cilvēki, taču, sastādot statistikas pārskatu, tiks ņemts vērā tikai noteikta cilvēku skaita viedoklis, kurš atbildīs noteiktajām prasībām.

Varbūtības paraugi
Varbūtības paraugiem tiek aprēķināta virkneparametri, kuriem atbilst paraugā esošie objekti, un starp tiem dažādos veidos var izvēlēties tieši tos faktus un datus, kas tiks parādīti kā izlases datu reprezentativitāte. Šādas nepieciešamo datu aprēķināšanas metodes var būt:
- Vienkārša izlases veida atlase.Tas sastāv no tā, ka starp izvēlēto segmentu nepieciešamais datu daudzums tiek izvēlēts ar pilnīgi nejaušas loterijas metodi, kas būs reprezentatīva izlase.
- Sistemātiska un izlases veida paraugu ņemšana dodspēja sastādīt sistēmu nepieciešamo datu aprēķināšanai, pamatojoties uz nejauši izvēlētu segmentu. Tādējādi, ja pirmais nejaušais skaitlis, kas norāda no kopējās populācijas izvēlēto datu kārtas numuru, ir 5, tad nākamie atlasāmie dati varētu būt, piemēram, 15, 25, 35 utt. Šis piemērs skaidri paskaidro, ka pat nejaušas izvēles pamatā var būt sistemātiski nepieciešamo ievades datu aprēķini.
Patērētāju paraugs
Nozīmīga paraugu ņemšana ir veids, kāir apsvērt katru atsevišķu segmentu, un, pamatojoties uz tā novērtējumu, tiek sastādīts kopums, kas atspoguļo kopējās datu bāzes īpašības un īpašības. Tādējādi tiek savākts vairāk datu, kas atbilst reprezentatīvās izlases prasībām. Jūs varat viegli izvēlēties vairākas iespējas, kas netiks iekļautas kopsummā, nezaudējot atlasīto datu kvalitāti, kas atspoguļo vispārējo populāciju. Tādā veidā tiek noteikta pētījumu rezultātu reprezentativitāte.
Parauga lielums
Ne pēdējais jāatrisina jautājums -tas ir izlases lielums reprezentatīvai iedzīvotāju pārstāvībai. Izlases lielums ne vienmēr ir atkarīgs no avotu skaita vispārējā populācijā. Tomēr izlases kopas reprezentativitāte tieši atkarīga no tā, cik segmentos rezultāts galu galā būtu jāsadala. Jo vairāk šādu segmentu ir, jo vairāk datu iekļauj iegūtajā izlasē. Ja rezultāti prasa vispārīgu apzīmējumu un neprasa specifiskumu, attiecīgi izlase kļūst mazāka, jo, neiedziļinoties detaļās, informācija tiek pasniegta virspusēji, kas nozīmē, ka tās lasījums būs vispārīgs.

Reprezentativitātes kļūdas jēdziens
Pārstāvības kļūda ir specifiskaneatbilstība starp vispārējās populācijas raksturlielumiem un izlases datiem. Veicot jebkuru izlases pētījumu, nav iespējams iegūt absolūti precīzus datus, piemēram, pilnīgā vispārējo populāciju pētījumā un izlasē, kuru pārstāv tikai daļa informācijas un parametru, savukārt detalizētāks pētījums ir iespējams tikai tad, ja tiek pētīta visa populācija . Tādējādi dažas kļūdas un kļūdas ir neizbēgamas.
Kļūdu veidi
Apkopojot reprezentatīvu izlasi, rodas dažas kļūdas:
- Sistemātiski.
- Nejaušs.
- Tīšs.
- Neapzināti.
- Standarta.
- Ierobežot.
Nejaušo kļūdu parādīšanās iemesls var būt vispārējās populācijas pētījuma pārtraukums. Parasti nejauša reprezentativitātes kļūda ir maza izmēra un rakstura.
Tikmēr sistemātiskas kļūdas rodas, ja tiek pārkāpti noteikumi par datu atlasi no vispārējās populācijas.

Vidējā kļūda ir starpība starp vidējoizlases un galvenās populācijas vērtības. Tas nav atkarīgs no izlases vienību skaita. Tas ir apgriezti proporcionāls izlases lielumam. Tad, jo lielāks ir tilpums, jo mazāka ir vidējās kļūdas vērtība.
Marginālā kļūda ir vislielākā iespējamāstarpība starp vidējo paraugu un kopējo populāciju. Šādu kļūdu raksturo kā iespējamo kļūdu maksimumu noteiktos to rašanās apstākļos.
Tīšas un netīšas reprezentativitātes kļūdas
Datu neobjektivitātes kļūdas var būt tīšas vai netīšas.
Tad apzinātu kļūdu parādīšanās iemesliir uz tendencēm balstīta datu vākšanas pieeja. Neparedzētas kļūdas rodas pat selektīvās novērošanas, reprezentatīvās izlases veidošanās sagatavošanas stadijā. Lai izvairītos no šādām kļūdām, jāizveido labs izlases ietvars izlases vienību sarakstiem. Tam pilnībā jāatbilst paraugu ņemšanas mērķiem, jābūt uzticamam, aptverot visus pētījuma aspektus.
Derīgums, uzticamība, reprezentativitāte. Kļūdas aprēķins
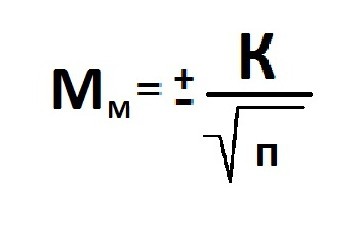
Aritmētiskā vidējā (M) reprezentativitātes kļūdas (Mm) aprēķins.
Standarta novirze: izlases lielums (> 30).
Reprezentatīva kļūda (Мр) un relatīvā vērtība (Р): izlases lielums (n> 30).
Gadījumā, ja nepieciešams izpētīt populāciju, kuras izlases lielums ir mazs un mazāks par 30 vienībām, novērojumu skaits samazināsies par vienu vienību.
Kļūdas lielums ir tieši proporcionāls izlases lielumam. Informācijas reprezentativitāte un precīzas prognozes iespējamības pakāpes aprēķins atspoguļo noteiktu robežas kļūdas vērtību.

Reprezentatīvās sistēmas
Ne tikai informācijas sniegšanas novērtēšanas procesātiek izmantota reprezentatīva izlase, bet persona, kas saņem informāciju, pati izmanto reprezentatīvas sistēmas. Tādējādi smadzenes apstrādā noteiktu informācijas daudzumu, izveidojot reprezentatīvu paraugu no visas informācijas plūsmas, lai kvalitatīvi un ātri novērtētu sniegtos datus un izprastu jautājuma būtību. Atbildiet uz jautājumu: "Pārstāvība - kas tas ir?" - cilvēka apziņas mērogā tas ir pavisam vienkārši. Tam smadzenes izmanto visus pakārtotos maņu orgānus, atkarībā no tā, kāda veida informācija ir jāizolē no vispārējās plūsmas. Tādējādi tiek nošķirti:

- Vizuāla attēlojuma sistēma, kurtiek iesaistīti acs vizuālās uztveres orgāni. Cilvēkus, kuri bieži izmanto šo sistēmu, sauc par vizuālo. Ar šīs sistēmas palīdzību cilvēks apstrādā informāciju, kas nāk attēlu veidā.
- Dzirdes reprezentācijas sistēma.Galvenais izmantotais orgāns ir dzirde. Informāciju, kas tiek sniegta skaņas failu vai runas veidā, apstrādā šī konkrētā sistēma. Cilvēkus, kuri informāciju labāk uztver pēc auss, sauc par audiāliem.
- Kinestētiskā attēlojuma sistēma ir informācijas plūsmas apstrāde, to uztverot caur ožas un taustes kanāliem.
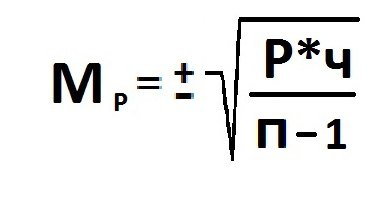
- Digitālā attēlojuma sistēma tiek izmantota kopā ar citiem kā līdzeklis informācijas iegūšanai no ārpuses. Tā ir subjektīvi loģiska iegūto datu uztvere un izpratne.

Tātad, kas ir reprezentativitāte?Vienkārša izvēle no kopas vai neatņemama procedūra informācijas apstrādē? Mēs varam viennozīmīgi teikt, ka reprezentativitāte lielā mērā nosaka mūsu uztveri par datu plūsmām, palīdzot no tā izolēt vissvarīgākos un nozīmīgākos.








