किसी भी कोशिका और जीव में, सभी विशेषताएंसंरचनात्मक, रूपात्मक और कार्यात्मक प्रकृति उनमें शामिल प्रोटीन की संरचना से निर्धारित होती है। शरीर की वंशानुगत संपत्ति कुछ प्रोटीनों को संश्लेषित करने की क्षमता है। डीएनए अणु में, अमीनो एसिड पॉलीपेप्टाइड श्रृंखला में स्थित होते हैं, जिस पर जैविक विशेषताएं निर्भर करती हैं।
प्रत्येक कोशिका का अपना होता हैडीएनए की पोलीन्यूक्लियोटाइड श्रृंखला में न्यूक्लियोटाइड का अनुक्रम। यह डीएनए का जेनेटिक कोड है। इसके माध्यम से कुछ प्रोटीनों के संश्लेषण की जानकारी दर्ज की जाती है। यह लेख बताता है कि आनुवंशिक कोड क्या है, इसके गुण और आनुवंशिक जानकारी।
इतिहास का थोड़ा सा
यह विचार कि एक आनुवंशिक कोड हो सकता हैअस्तित्व, बीसवीं शताब्दी के मध्य में जे। गामो और ए। डाउन द्वारा तैयार किया गया था। उन्होंने वर्णन किया कि एक विशेष अमीनो एसिड के संश्लेषण के लिए जिम्मेदार न्यूक्लियोटाइड अनुक्रम में कम से कम तीन इकाइयाँ होती हैं। बाद में, उन्होंने तीन न्यूक्लियोटाइड्स की सटीक संख्या साबित की (यह आनुवंशिक कोड की एक इकाई है), जिसे ट्रिपल या कोडन कहा जाता था। कुल मिलाकर चौंसठ न्यूक्लियोटाइड होते हैं, क्योंकि एसिड अणु, जहां प्रोटीन या आरएनए संश्लेषण होता है, में चार अलग-अलग न्यूक्लियोटाइड के अवशेष होते हैं।

आनुवंशिक कोड क्या है
न्यूक्लियोटाइड अनुक्रम के कारण अमीनो एसिड के प्रोटीन अनुक्रम को कोडित करने का तरीका सभी जीवित कोशिकाओं और जीवों की विशेषता है। यही आनुवंशिक कोड है।
डीएनए में चार न्यूक्लियोटाइड होते हैं:
- एडेनिन - ए;
- ग्वानिन - जी;
- साइटोसिन - सी;
- थाइमिन - टी.
उन्हें लैटिन या (रूसी भाषा के साहित्य में) रूसी में बड़े अक्षरों द्वारा नामित किया गया है।
आरएनए में भी चार न्यूक्लियोटाइड होते हैं, लेकिन उनमें से एक डीएनए से अलग होता है:
- एडेनिन - ए;
- ग्वानिन - जी;
- साइटोसिन - सी;
- यूरेसिल - यू.
सभी न्यूक्लियोटाइड जंजीरों में पंक्तिबद्ध होते हैं, और डीएनए में एक डबल हेलिक्स और आरएनए में एक एकल हेलिक्स प्राप्त होता है।
प्रोटीन बीस अमीनो एसिड पर निर्मित होते हैं, जहां वे एक निश्चित क्रम में स्थित होते हैं, इसके जैविक गुणों को निर्धारित करते हैं।

आनुवंशिक कोड के गुण
तिहरापन।आनुवंशिक कोड की इकाई में तीन अक्षर होते हैं, यह ट्रिपल है। इसका मतलब है कि बीस मौजूदा अमीनो एसिड तीन विशिष्ट न्यूक्लियोटाइड के साथ एन्कोडेड हैं जिन्हें कोडन या ट्रिलपेट कहा जाता है। चौंसठ संयोजन हैं जो चार न्यूक्लियोटाइड से बनाए जा सकते हैं। यह मात्रा बीस अमीनो एसिड को एनकोड करने के लिए पर्याप्त से अधिक है।
अध: पतन। प्रत्येक अमीनो एसिड मेथियोनीन और ट्रिप्टोफैन के अपवाद के साथ एक से अधिक कोडन से मेल खाता है।
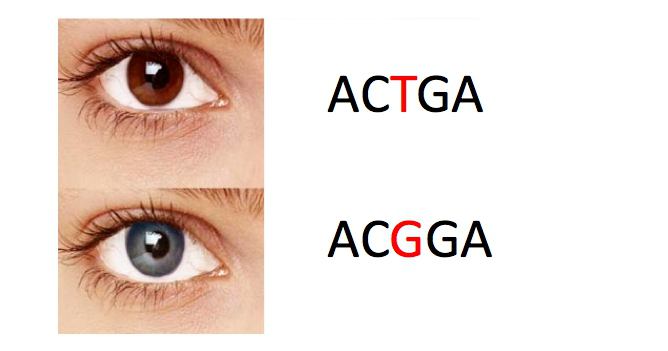
अस्पष्टता।एक कोडन एक अमीनो एसिड को एन्क्रिप्ट करता है। उदाहरण के लिए, एक स्वस्थ व्यक्ति के जीन में हीमोग्लोबिन के बीटा लक्ष्य के बारे में जानकारी होती है, ट्रिपल GAG और GAA ग्लूटामिक एसिड को एनकोड करता है। और सिकल सेल एनीमिया से पीड़ित हर व्यक्ति में एक न्यूक्लियोटाइड बदल दिया जाता है।
समरूपता। अमीनो एसिड अनुक्रम हमेशा न्यूक्लियोटाइड अनुक्रम से मेल खाता है जिसमें जीन होता है।
आनुवंशिक कोड निरंतर और सघन होता है, जोइसका मतलब है कि इसमें कोई "विराम चिह्न" नहीं है। अर्थात्, एक निश्चित कोडन से शुरू होकर, एक निरंतर पठन होता है। उदाहरण के लिए, AUGGUGTSUUAAUGUG को इस प्रकार पढ़ा जाएगा: AUG, GUG, TSUU, AAU, GUG। लेकिन AUG, UGG वगैरह या किसी अन्य तरीके से नहीं।
बहुमुखी प्रतिभा। यह मानव से लेकर मछली, कवक और बैक्टीरिया तक सभी स्थलीय जीवों के लिए समान है।
टेबल
नीचे दी गई तालिका में सभी शामिल नहीं हैंउपलब्ध अमीनो एसिड। Hydroxyproline, hydroxylysine, phosphoserine, tyrosine iodo डेरिवेटिव, cystine और कुछ अन्य अनुपस्थित हैं, क्योंकि वे mRNA द्वारा एन्कोड किए गए अन्य अमीनो एसिड के डेरिवेटिव हैं और अनुवाद के परिणामस्वरूप प्रोटीन संशोधन के बाद बनते हैं।
आनुवंशिक कूट के गुणों से ज्ञात होता है कि एककोडन एक एमिनो एसिड को एन्कोड करने में सक्षम है। अपवाद आनुवंशिक कोड है, जो अतिरिक्त कार्य करता है और वेलिन और मेथियोनीन को एन्कोड करता है। आईआरएनए, एक कोडन के साथ शुरुआत में होने के कारण, टी-आरएनए को जोड़ता है, जो फॉर्मिलमेथियोन को वहन करता है। संश्लेषण के पूरा होने पर, यह अपने आप से अलग हो जाता है और फॉर्माइल अवशेषों को पकड़ लेता है, जिसे मेथियोनीन अवशेषों में परिवर्तित किया जाता है। इस प्रकार, उपरोक्त कोडन पॉलीपेप्टाइड श्रृंखला संश्लेषण के आरंभकर्ता हैं। अगर वे शुरुआत में नहीं हैं, तो वे दूसरों से अलग नहीं हैं।

आनुवंशिक जानकारी
यह अवधारणा एक संपत्ति कार्यक्रम को संदर्भित करती है जिसे पूर्वजों से पारित किया जाता है। यह आनुवंशिकता में आनुवंशिक कोड के रूप में अंतर्निहित है।
प्रोटीन संश्लेषण के दौरान आरएनए (राइबोन्यूक्लिक एसिड) का आनुवंशिक कोड लागू किया जाता है:
- सूचनात्मक आई-आरएनए;
- परिवहन टी-आरएनए;
- राइबोसोमल आर-आरएनए।
सूचना सीधे संचार (डीएनए-आरएनए-प्रोटीन) और रिवर्स (पर्यावरण-प्रोटीन-डीएनए) द्वारा प्रेषित होती है।
जीव इसे प्राप्त कर सकते हैं, स्टोर कर सकते हैं, संचारित कर सकते हैं और इसका सबसे कुशलता से उपयोग कर सकते हैं।
विरासत से, जानकारी निर्धारित करती हैएक जीव का विकास। लेकिन पर्यावरण के साथ अंतःक्रिया के कारण उत्तरार्द्ध की प्रतिक्रिया विकृत हो जाती है, जिसके कारण विकास और विकास होता है। इस प्रकार, नई जानकारी शरीर में डाली जाती है।
आणविक जीव विज्ञान के नियमों की गणनाऔर आनुवंशिक कोड की खोज ने स्पष्ट किया कि आनुवंशिकी को डार्विन के सिद्धांत के साथ जोड़ना आवश्यक है, जिसके आधार पर विकास का एक सिंथेटिक सिद्धांत - गैर-शास्त्रीय जीव विज्ञान - उभरा।
आनुवंशिकता, परिवर्तनशीलता और प्राकृतिकडार्विन का चयन आनुवंशिक रूप से निर्धारित चयन द्वारा पूरक है। विकास आनुवंशिक स्तर पर यादृच्छिक उत्परिवर्तन और सबसे मूल्यवान लक्षणों की विरासत के माध्यम से महसूस किया जाता है जो पर्यावरण के लिए सबसे अधिक अनुकूलित होते हैं।
किसी व्यक्ति में कोड को डिकोड करना
नब्बे के दशक में, मानव जीनोम परियोजना शुरू की गई थी,नतीजतन, 2000 के दशक में, 99.99% मानव जीन वाले जीनोम के टुकड़े खोजे गए। टुकड़े जो प्रोटीन संश्लेषण में शामिल नहीं हैं और एन्कोडेड नहीं हैं अज्ञात बने रहे। उनकी भूमिका अभी भी अज्ञात है।
ऐसे अध्ययनों की भूमिका को शायद ही कम करके आंका जा सकता है।जब उन्होंने पता लगाया कि आनुवंशिक कोड क्या है, तो यह ज्ञात हो गया कि विकास किस पैटर्न से होता है, कैसे रूपात्मक संरचना, मानस, कुछ बीमारियों की प्रवृत्ति, चयापचय और व्यक्तियों के दोष बनते हैं।