इससे पहले कि हम इस तरह की अवधारणा के बारे में जानेंडेटा मॉडल, हम उनके प्रकारों, वर्गीकरणों का अध्ययन करेंगे, और एक विस्तृत विवरण पर भी विचार करेंगे, सूचना विज्ञान के बहुत अर्थ को समझने की आवश्यकता है, जिसमें ये अवधारणाएं और इसके द्वारा अध्ययन किए गए सभी क्षेत्र शामिल हैं। इस लेख में, हम इस विज्ञान के मूल नियमों और स्तंभों पर विचार करेंगे, विशेष रूप से, हम डेटा संरचनाओं के प्रकार, उनमें संबंध और बहुत कुछ के बारे में बात करेंगे।
सूचना और कंप्यूटर विज्ञान क्या है?

डेटा मॉडल की संरचना का अध्ययन करने के लिए आगे बढ़ने के लिए, आपको यह समझने की आवश्यकता है कि यह डेटा और जानकारी सिद्धांत रूप में क्या है।
अस्तित्व के किसी भी क्षण मेंमानव समाज में, सूचना ने एक बड़ी भूमिका निभाई है, अर्थात्, हमारे आसपास की विशाल और विविध दुनिया से एक व्यक्ति द्वारा प्राप्त जानकारी। उदाहरण के लिए, आदिम लोग भी शैल चित्रों की सहायता से अपने जीवन के सरलतम तरीके और परंपराओं के बारे में जानकारी हमारे लिए छोड़ गए।
तब से, लोगों ने कई वैज्ञानिक प्रदर्शन किए हैंखोजों, अपने पूर्ववर्तियों के बारे में जानकारी एकत्र की और रोजमर्रा की खबरों से संचित जानकारी, जिससे अधिक से अधिक मात्रा में जानकारी प्राप्त हुई और इसे मूल्य और विश्वसनीयता जैसे गुण दिए गए।
समय के साथ, जानकारी की मात्रा इतनी हो गई हैइतना विशाल और विशाल कि मानवता इसे अपनी स्मृति में स्वतंत्र रूप से संग्रहीत करने, मैन्युअल प्रसंस्करण में संलग्न होने और इस पर कोई कार्रवाई करने में सक्षम नहीं थी। इसीलिए आज के मौलिक विज्ञान - सूचना विज्ञान की आवश्यकता उत्पन्न हुई, जिसके अध्ययन के क्षेत्र में सूचना के विभिन्न परिवर्तनों से जुड़ी मानव गतिविधि का क्षेत्र शामिल है। कंप्यूटर विज्ञान हमारे जीवन के लगभग हर क्षेत्र को कवर करता है: सरल गणितीय गणना करने से लेकर जटिल इंजीनियरिंग और वास्तुशिल्प डिजाइन तक, साथ ही साथ एनिमेशन और कार्टून बनाना। यह स्वचालित प्रसंस्करण, संरचना, भंडारण और सूचना के प्रसारण जैसे बुनियादी लक्ष्य निर्धारित करता है।
आज के विषय में, हम विशेष रूप से स्पर्श करेंगेसंरचना की जानकारी, अर्थात्, डेटा मॉडल के बारे में बात करते हैं। हालांकि, उससे पहले हमारी बातचीत के विषय से सीधे जुड़े कुछ अन्य बिंदुओं को स्पष्ट करना आवश्यक है। अर्थात्: डेटाबेस और डीबीएमएस।
डेटाबेस और डीबीएमएस
संरचित जानकारी का प्रकार डेटाबेस (DB) है।
शब्द का अर्थ है एक साझा सेटजानकारी जो तार्किक रूप से एक दूसरे से संबंधित है। डेटाबेस संरचनाएं हैं जो सक्रिय रूप से गतिशील साइटों में बड़ी मात्रा में जानकारी के साथ उपयोग की जाती हैं। उदाहरण के लिए, ये विभिन्न ऑनलाइन स्टोर, मीडिया पोर्टल या अन्य कॉर्पोरेट स्रोतों के संसाधन हैं।

डेटाबेस प्रबंधन प्रणाली (डीबीएमएस)डेटाबेस बनाने, उन्हें उचित रूप में बनाए रखने और उनमें आवश्यक जानकारी के लिए त्वरित खोज को व्यवस्थित करने के लिए डिज़ाइन किए गए विभिन्न सॉफ़्टवेयर का एक सेट कहलाता है। व्यापक रूप से उपयोग किए जाने वाले DBMS का एक उदाहरण Microsoft Access है, जो Microsoft Office की एक पंक्ति में निर्मित होता है। इस DBMS की एक विशिष्ट विशेषता यह है कि, इसमें VBA भाषा की उपस्थिति के कारण, डेटाबेस के आधार पर काम करते हुए, Access में ही एप्लिकेशन बनाने की परिकल्पना की गई है।

डेटाबेस को कई अलग-अलग मानदंडों के अनुसार वर्गीकृत किया जा सकता है:
- मॉडल के प्रकार से (उन पर चर्चा की जाएगी)।
- भंडारण स्थान (हार्ड ड्राइव, रैम, ऑप्टिकल डिस्क) द्वारा।
- उपयोग के प्रकार से (स्थानीय, यानी, तक पहुंचएक उपयोगकर्ता के पास है; माध्यम, यानी डेटाबेस में डेटा कई लोगों द्वारा देखा जा सकता है; सामान्य - ऐसे डेटाबेस कई सर्वरों और पर्सनल कंप्यूटरों पर स्थित होते हैं, यानी बड़ी संख्या में लोगों को उनमें जानकारी देखने का अधिकार होता है)।
- सूचना की सामग्री (वैज्ञानिक, ऐतिहासिक, शब्दावली और अन्य) द्वारा।
- आधार (केंद्रीकृत और वितरित) की निश्चितता की डिग्री से।
- एकरूपता द्वारा (क्रमशः विषम और सजातीय)।
और कई अन्य, कम महत्वपूर्ण संकेतों पर भी।
ऐसे डेटाबेस का मुख्य भाग डेटा मॉडल है।वे इसके प्रसंस्करण के लिए सूचना संरचनाओं और संचालन के एक सेट का प्रतिनिधित्व करते हैं, आवश्यक जानकारी के लिए खोज को व्यवस्थित करने की प्रक्रिया को सरल और तेज करते हैं।
डेटा सिस्टम मॉडल: वर्गीकरण
विभिन्न प्रकार के डेटाबेस हैं, लेकिन सभीवे अधिक सामान्य और मौलिक मॉडल पर आधारित हैं। सूचना डेटा मॉडल का वर्गीकरण भी कई अलग-अलग प्रकारों में विभाजित है। यहां सबसे अधिक इस्तेमाल की जाने वाली श्रेणियां हैं:
- पदानुक्रमित मॉडल;
- नेटवर्क आरेख;
- संबंधपरक मॉडल;
- वस्तु उन्मुख स्कीमा।
इन सभी प्रकार के डेटा मॉडल में जानकारी की प्रस्तुति और भंडारण की प्रकृति में आपस में भिन्नता है।
सही मॉडल चुनने के लिए मानदंड
उपयोगकर्ता उपरोक्त में से किसी भी प्रकार के साथ एक डेटाबेस बना सकता है। हालांकि, यह ध्यान दिया जाना चाहिए कि डेटा मॉडल का चुनाव कुछ कारकों पर निर्भरता निर्धारित करता है।
सबसे महत्वपूर्ण मानदंड हैक्लाइंट द्वारा उपयोग किया जाने वाला डीबीएमएस किसी विशेष मॉडल का समर्थन करता है या नहीं। अधिकांश DBMS इसलिए बनाए जाते हैं ताकि उपयोगकर्ता को एक डेटा मॉडल के साथ प्रस्तुत किया जाए जिसका उपयोग किया जाना चाहिए, हालांकि उनमें से कुछ एक साथ कई अलग-अलग समकक्षों का समर्थन करते हैं। आइए उनकी विशेषताओं को अलग से देखें।
पदानुक्रमित मॉडल

यह डेटा प्रस्तुति मॉडल के प्रकारों में से एक है, जो उन्हें तत्वों के एक सेट के रूप में व्यवस्थित करता है, जो सामान्य से विशिष्ट के क्रम में व्यवस्थित होते हैं।
संरचना एक उल्टा पेड़ है। एक विशिष्ट फ़ाइल तक पहुँचने के लिए एक पथ है।
एक पदानुक्रमित मॉडल को तीन बुनियादी शर्तों को पूरा करना चाहिए:
- प्रत्येक निचले स्तर के नोड को केवल एक उच्च-स्तरीय नोड से जोड़ा जा सकता है।
- पदानुक्रम में केवल एक मुख्य रूट नोड होता है, जो किसी अन्य नोड के अधीनस्थ नहीं होता है और उच्चतम स्तर पर होता है।
- रूट नोड से पदानुक्रम में किसी भी नोड तक केवल एक पथ है।
संबंध प्रकार एक-से-अनेक है।
नेटवर्क मॉडल
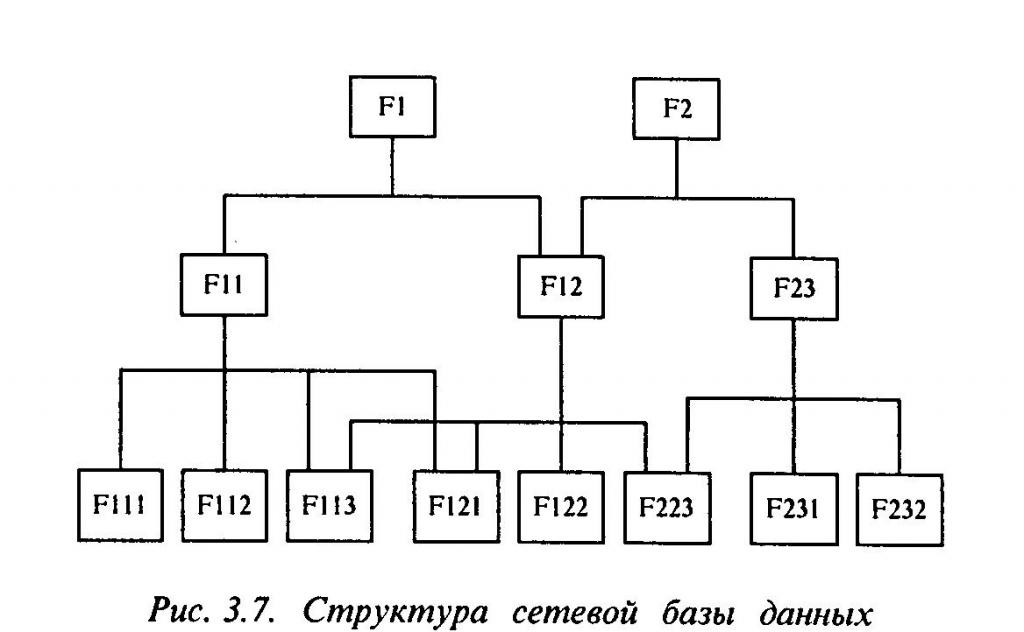
यह पदानुक्रमित संरचना पर बहुत अधिक निर्भर करता है, जिसमेंइसमें बहुत कुछ समान है। उनके बीच मुख्य अंतर संबंध के प्रकार का है, जिसका अर्थ है कई-से-अनेक संबंध, अर्थात, विभिन्न नोड्स के बीच संबंध मौजूद हो सकते हैं।
नेटवर्क मॉडल का लाभ यह है कि यह अन्य मॉडलों की तुलना में मेमोरी और ऑपरेटिंग समय के मामले में कम पीसी संसाधनों की खपत करता है।
इस योजना का नुकसान यह है कियदि आपको संग्रहीत डेटा की संरचना को बदलने की आवश्यकता है, तो आपको इस नेटवर्क मॉडल के आधार पर सभी एप्लिकेशन को बदलना होगा, क्योंकि ऐसी संरचना स्वतंत्र नहीं है।
संबंधपरक मॉडल

आज सबसे आम हैदिन। इस तरह के डेटा मॉडल में वस्तुओं और उनके बीच संबंधों को तालिकाओं द्वारा दर्शाया जाता है, और उनमें संबंधों को वस्तुओं के रूप में माना जाता है। ऐसी तालिका के स्तंभों को फ़ील्ड कहा जाता है, और पंक्तियों को रिकॉर्ड कहा जाता है। संबंधपरक मॉडल की प्रत्येक तालिका को निम्नलिखित गुणों को पूरा करना चाहिए:
- बिल्कुल इसके सभी स्तंभ सजातीय हैं, अर्थात एक ही स्तंभ में स्थित सभी तत्वों का एक ही प्रकार और अधिकतम आकार होना चाहिए।
- प्रत्येक स्तंभ का अपना विशिष्ट नाम होता है।
- तालिका में समान पंक्तियाँ नहीं होनी चाहिए।
- तालिका में पंक्तियों और स्तंभों के प्रकट होने का क्रम मनमाना हो सकता है।
संबंधपरक मॉडल इन तालिकाओं के बीच संबंधों के प्रकारों को भी ध्यान में रखता है, जिसमें एक-से-एक, एक-से-अनेक, और अनेक-से-अनेक संबंध शामिल हैं।
एक सारणीबद्ध संबंधपरक मॉडल के आधार पर बनाए गए डेटाबेस लचीले, अनुकूलनीय और अत्यधिक मापनीय होते हैं। प्रत्येक डेटा ऑब्जेक्ट को सबसे छोटे और सबसे उपयोगी विखंडू में विभाजित किया जाता है।
वस्तु उन्मुख मॉडल
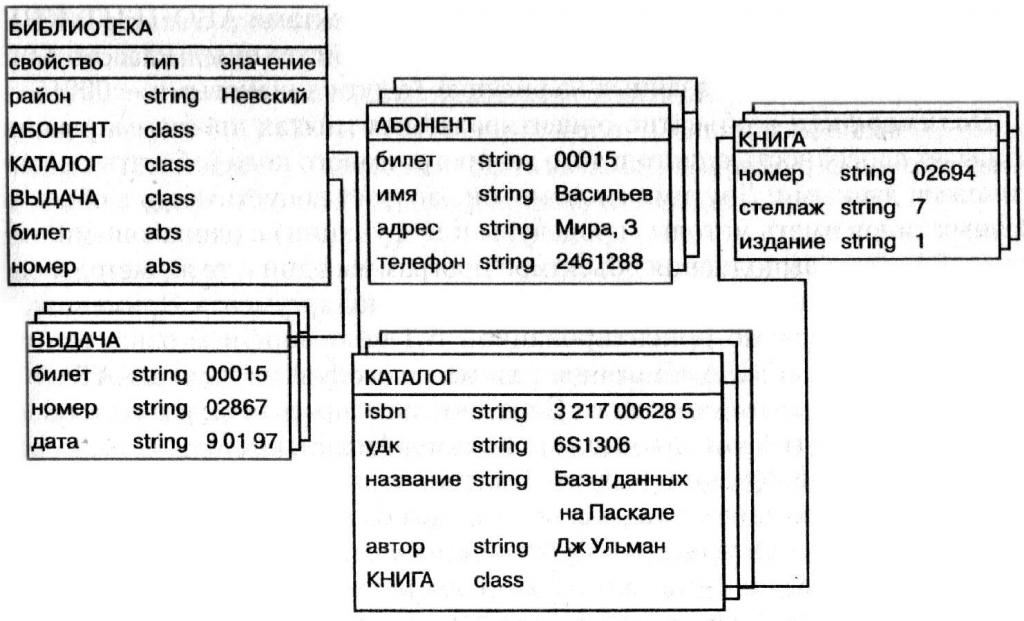
ऑब्जेक्ट-ओरिएंटेड बिल्ड मॉडल मेंडेटाबेस डेटा को संबद्ध कार्यों के साथ पुन: प्रयोज्य सॉफ़्टवेयर तत्वों के संग्रह द्वारा परिभाषित किया जाता है। कई अलग-अलग ऑब्जेक्ट-ओरिएंटेड डेटाबेस हैं:
- मल्टीमीडिया डेटाबेस।
- हाइपरटेक्स्ट डेटाबेस।
पहले में मीडिया डेटा शामिल है। इसमें विभिन्न छवियां हो सकती हैं, उदाहरण के लिए, एक संबंधपरक मॉडल में संग्रहीत नहीं किया जा सकता है।
हाइपरटेक्स्ट डेटाबेस किसी को भी अनुमति देता हैमूल वस्तु को किसी अन्य वस्तु से जोड़ा जाना। असमान डेटा के एक सेट में संचार को व्यवस्थित करने के लिए यह काफी सुविधाजनक है, लेकिन संख्यात्मक विश्लेषण करते समय ऐसा मॉडल आदर्श से बहुत दूर है।
शायद वस्तु-उन्मुख सबसे अधिक हैलोकप्रिय और प्रयुक्त मॉडल, क्योंकि इसमें तालिकाओं के रूप में जानकारी हो सकती है, जैसे संबंधपरक, लेकिन, इसके विपरीत, तालिका रिकॉर्ड तक सीमित नहीं है।
कुछ अतिरिक्त जानकारी
कंप्यूटर विज्ञान में पहली बार आईबीएम द्वारा पिछली शताब्दी के 60 के दशक में पदानुक्रमित मॉडल का उपयोग किया गया था, लेकिन आज इसकी लोकप्रियता कम दक्षता के कारण कम हो गई है।
डेटाबेस सिस्टम भाषाओं पर सम्मेलन द्वारा औपचारिक रूप से परिभाषित किए जाने के बाद, नेटवर्क डेटा मॉडल 1970 के दशक से लोकप्रिय है।
रिलेशनल डेटाबेस आमतौर पर स्ट्रक्चर्ड क्वेरी लैंग्वेज (एसक्यूएल) में लिखे जाते हैं। यह मॉडल 1970 में प्रकाशित हुआ था।
निष्कर्ष
इस प्रकार, हम निम्नलिखित संक्षिप्त निष्कर्षों के साथ उन मुद्दों को संक्षेप में प्रस्तुत कर सकते हैं जिन पर हमने आज विचार किया है:
- पर्सनल कंप्यूटर (पीसी) पर डेटा को विशेष डेटाबेस के रूप में संरचनात्मक रूप से संग्रहीत किया जा सकता है।
- किसी भी डेटाबेस का मूल उसका मॉडल होता है।
- चार मुख्य प्रकार के डेटा मॉडल हैं: पदानुक्रमित, नेटवर्क, संबंधपरक, वस्तु-उन्मुख।
- एक पदानुक्रमित मॉडल में, संरचना बाह्य रूप से एक उल्टा पेड़ है।
- नेटवर्क मॉडल में, विभिन्न नोड्स के बीच कनेक्शन होते हैं।
- संबंधपरक मॉडल में, वस्तुओं के बीच संबंधों को तालिकाओं के रूप में दर्शाया जाता है।
- ऑब्जेक्ट-ओरिएंटेड मॉडल में, तत्वों के बीच संबंधों को तालिकाओं द्वारा दर्शाया जा सकता है, लेकिन उन तक सीमित नहीं है।
बाद के मामले में, उदाहरण के लिए, पाठ और चित्र हो सकते हैं।




