हमारे में कंप्यूटर प्रौद्योगिकी का उदयआधुनिकता ने मानव गतिविधि के सभी क्षेत्रों में सूचना क्रांति को चिह्नित किया है। लेकिन वैश्विक इंटरनेट पर सभी सूचनाओं को अनावश्यक कचरा बनने से रोकने के लिए, एक डेटाबेस सिस्टम का आविष्कार किया गया, जिसमें सामग्री को क्रमबद्ध, व्यवस्थित किया जाता है, जिसके परिणामस्वरूप उन्हें आसानी से पाया जा सकता है और बाद के प्रसंस्करण के लिए प्रस्तुत किया जा सकता है। तीन मुख्य प्रकार हैं - संबंधपरक, श्रेणीबद्ध, नेटवर्क डेटाबेस प्रतिष्ठित हैं।
मौलिक मॉडल
डेटाबेस की उत्पत्ति पर वापस जा रहे हैं, यह इसके लायक हैयह कहने के लिए कि यह प्रक्रिया काफी जटिल थी, यह प्रोग्राम करने योग्य सूचना प्रसंस्करण उपकरण के विकास से उत्पन्न होती है। इसलिए, यह आश्चर्य की बात नहीं है कि इस समय उनके मॉडलों की संख्या 50 से अधिक तक पहुंचती है, लेकिन मुख्य श्रेणीबद्ध, संबंधपरक और नेटवर्क मॉडल हैं, जो अभी भी व्यापक रूप से व्यवहार में उपयोग किए जाते हैं। वे क्या हैं?
पदानुक्रमित डेटाबेस में एक पेड़ जैसा होता हैसंरचना और विभिन्न स्तरों के डेटा से बना है, जिसके बीच संबंध हैं। DB नेटवर्क मॉडल एक अधिक जटिल पैटर्न है। इसकी संरचना एक पदानुक्रम जैसा दिखती है, और योजना का विस्तार और सुधार किया जाता है। उनके बीच अंतर यह है कि एक पदानुक्रमित मॉडल के वंशानुगत डेटा का केवल एक पूर्वज के साथ संबंध हो सकता है, जबकि नेटवर्क डेटा में कई हो सकते हैं। एक रिलेशनल डेटाबेस की संरचना बहुत अधिक जटिल है। इसलिए, इसका अधिक विस्तार से विश्लेषण किया जाना चाहिए।

एक संबंधपरक डेटाबेस की मूल अवधारणा
यह मॉडल 1970 के दशक में विकसित किया गया था।एडगर कॉड, डॉक्टर ऑफ साइंस द्वारा। यह एक तार्किक रूप से संरचित तालिका है जिसमें डेटा का वर्णन करने वाले क्षेत्र, एक दूसरे के साथ उनके संबंध, उन पर किए गए संचालन और सबसे महत्वपूर्ण बात यह है कि नियम जो उनकी अखंडता की गारंटी देते हैं। मॉडल को रिलेशनल क्यों कहा जाता है? यह डेटा के बीच संबंधों (अक्षांश से। Relatio से) पर आधारित है। इस प्रकार के डेटाबेस की कई परिभाषाएँ हैं। सूचना के साथ संबंधपरक तालिकाओं को नेटवर्क या पदानुक्रमित मॉडल की तुलना में व्यवस्थित और संसाधित करना बहुत आसान होता है। यह कैसे किया जा सकता है? यह सुविधाओं, मॉडल की संरचना और संबंधपरक तालिकाओं के गुणों को जानने के लिए पर्याप्त है।

मॉडलिंग और मुख्य तत्वों को चित्रित करने की प्रक्रिया
अपना खुद का DBMS बनाने के लिए, आपको चाहिएमॉडलिंग टूल में से किसी एक का उपयोग करें, सोचें कि आपको किस जानकारी के साथ काम करने की आवश्यकता है, डिज़ाइन टेबल और डेटा के बीच संबंधपरक एकल और एकाधिक संबंध, इकाई सेल भरें और प्राथमिक, विदेशी कुंजी सेट करें।
टेबल मॉडलिंग और रिलेशनल डिजाइनडेटाबेस वर्कबेंच, PhpMyAdmin, Case Studio, dbForge Studio जैसे फ्री टूल्स के जरिए तैयार किए जाते हैं। विस्तृत डिजाइन के बाद, आपको ग्राफिक रूप से तैयार रिलेशनल मॉडल को सहेजना चाहिए और इसे तैयार एसक्यूएल कोड में अनुवाद करना चाहिए। इस स्तर पर, आप डेटा सॉर्टिंग, प्रोसेसिंग और सिस्टमैटाइजेशन के साथ काम करना शुरू कर सकते हैं।

संबंधपरक मॉडल से संबंधित विशेषताएं, संरचना और शर्तें
प्रत्येक स्रोत अपने तत्वों का अपने तरीके से वर्णन करता है, इसलिए कम भ्रम के लिए मैं एक छोटा संकेत देना चाहूंगा:
- संबंधपरक लेबल = इकाई;
- लेआउट = विशेषताएँ = फ़ील्ड नाम = इकाई स्तंभ शीर्षलेख;
- इकाई उदाहरण = टपल = रिकॉर्ड = तालिका पंक्ति;
- विशेषता मान = इकाई सेल = फ़ील्ड।

एक रिलेशनल डेटाबेस के गुणों को प्राप्त करने के लिए, आपको यह जानना होगा कि इसमें कौन से मूल घटक शामिल हैं और वे किस लिए हैं।
- सार।एक रिलेशनल डेटाबेस में एक टेबल हो सकती है, या टेबल का एक पूरा सेट हो सकता है जो वर्णित ऑब्जेक्ट्स को उनमें संग्रहीत डेटा के कारण चिह्नित करता है। उनके पास निश्चित संख्या में फ़ील्ड और रिकॉर्ड की एक चर संख्या है। एक रिलेशनल डेटाबेस मॉडल टेबल स्ट्रिंग्स, एट्रीब्यूट्स और एक लेआउट से बना होता है।
- रिकॉर्ड - डेटा प्रदर्शित करने वाली पंक्तियों की एक चर संख्या जो वर्णित वस्तु की विशेषता है। रिकॉर्ड्स को सिस्टम द्वारा स्वचालित रूप से क्रमांकित किया जाता है।
- विशेषताएँ वे डेटा हैं जो निकाय स्तंभों के विवरण को प्रदर्शित करते हैं।
- मैदान। एक इकाई कॉलम का प्रतिनिधित्व करता है। उनकी संख्या एक निश्चित मान है जो तालिका के निर्माण या संशोधन के दौरान निर्धारित की जाती है।

अब, तालिका के घटक तत्वों को जानकर, आप डेटाबेस रिलेशनल मॉडल के गुणों पर जा सकते हैं:
- संबंधपरक डेटाबेस इकाइयाँ द्वि-आयामी हैं। इस संपत्ति के लिए धन्यवाद, उनके साथ विभिन्न तार्किक और गणितीय संचालन करना आसान है।
- एक संबंधपरक तालिका में विशेषताओं और अभिलेखों के मूल्यों का क्रम मनमाना हो सकता है।
- एक संबंधपरक तालिका के भीतर एक स्तंभ का अपना व्यक्तिगत नाम होना चाहिए।
- किसी निकाय स्तंभ के सभी डेटा की एक निश्चित लंबाई और एक ही प्रकार होता है।
- किसी भी रिकॉर्ड को संक्षेप में एक डेटा आइटम माना जाता है।
- तार के घटक घटक अद्वितीय हैं। एक संबंधपरक इकाई में कोई डुप्लिकेट पंक्तियाँ नहीं हैं।
एक रिलेशनल DBMS के गुणों के आधार पर, यह स्पष्ट है कि विशेषता मान समान प्रकार और लंबाई के होने चाहिए। आइए विशेषता मानों की विशेषताओं पर विचार करें।
संबंधपरक डेटाबेस फ़ील्ड की मूल विशेषताएं characteristics
फ़ील्ड के नाम अद्वितीय होने चाहिएएक इकाई। संबंधपरक डेटाबेस विशेषता या फ़ील्ड प्रकार वर्णन करते हैं कि कौन सा श्रेणी डेटा निकाय फ़ील्ड में संग्रहीत है। एक रिलेशनल डेटाबेस फ़ील्ड में वर्णों में एक निश्चित आकार होना चाहिए। विशेषता मानों के पैरामीटर और प्रारूप यह निर्धारित करते हैं कि उनमें डेटा कैसे ठीक किया जाता है। "मास्क" या "इनपुट पैटर्न" जैसी कोई चीज भी होती है। इसका उद्देश्य विशेषता मान में डेटा प्रविष्टि के कॉन्फ़िगरेशन को परिभाषित करना है। यह आवश्यक है कि किसी फ़ील्ड में गलत डेटा प्रकार लिखते समय एक त्रुटि संदेश जारी किया जाए। साथ ही, फ़ील्ड के तत्वों पर कुछ प्रतिबंध लगाए गए हैं - सटीकता और त्रुटि मुक्त डेटा प्रविष्टि की जाँच के लिए शर्तें। कुछ आवश्यक विशेषता मान हैं जो स्पष्ट रूप से डेटा से भरे होने चाहिए। कुछ विशेषता तार NULL मानों से भरे जा सकते हैं। फ़ील्ड विशेषताओं में खाली डेटा दर्ज करने की अनुमति है। त्रुटि अधिसूचना की तरह, ऐसे मान हैं जो सिस्टम द्वारा स्वचालित रूप से भरे जाते हैं - यह डिफ़ॉल्ट डेटा है। एक अनुक्रमित फ़ील्ड का उद्देश्य किसी भी डेटा की खोज को गति देना है।

2डी रिलेशनल डेटाबेस टेबल स्कीमा
| विशेषता का नाम १ | विशेषता का नाम 2 | विशेषता का नाम 3 | विशेषता का नाम 4 | विशेषता का नाम 5 |
| आइटम_1_1 | आइटम_1_2 | आइटम_1_3 | मद_1_4 | मद_1_5 |
| आइटम_2_1 | आइटम_2_2 | आइटम_2_3 | आइटम_2_4 | आइटम_2_5 |
| आइटम_3_1 | आइटम_3_2 | आइटम_3_3 | मद_3_4 | मद_3_5 |
नियंत्रण प्रणाली की विस्तृत समझ के लिएउदाहरण के तौर पर SQL वाले मॉडल स्कीमा को देखने का सबसे अच्छा तरीका है। हम पहले से ही जानते हैं कि एक रिलेशनल डेटाबेस क्या है। प्रत्येक तालिका में एक रिकॉर्ड एक डेटा आइटम है। डेटा अतिरेक को रोकने के लिए, सामान्यीकरण संचालन करना आवश्यक है।
एक संबंधपरक इकाई को सामान्य करने के लिए बुनियादी नियम
1. एक संबंधपरक तालिका के लिए फ़ील्ड नाम का मान अद्वितीय होना चाहिए, एक तरह का (पहला सामान्य रूप 1NF है)।
2. एक तालिका के लिए जिसे पहले ही घटाकर 1NF कर दिया गया है, किसी भी गैर-पहचानने वाले कॉलम का नाम तालिका के विशिष्ट पहचानकर्ता (2NF) पर निर्भर होना चाहिए।
3. संपूर्ण तालिका के लिए जो पहले से ही 2NF में है, प्रत्येक गैर-पहचान करने वाला फ़ील्ड किसी अन्य अपरिचित मान (इकाई 3NF) के तत्व पर निर्भर नहीं हो सकता है।
डेटाबेस: तालिकाओं के बीच संबंधपरक संबंध
संबंधपरक तालिका संबंध के 2 मुख्य प्रकार हैं:
- एक-अनेक।तब होता है जब तालिका # 1 का एक कुंजी रिकॉर्ड दूसरी इकाई के कई उदाहरणों से मेल खाता है। खींची गई रेखा के एक छोर पर एक कुंजी चिह्न इंगित करता है कि इकाई "एक" तरफ है, रेखा के दूसरे छोर को अक्सर अनंत प्रतीक के साथ चिह्नित किया जाता है।
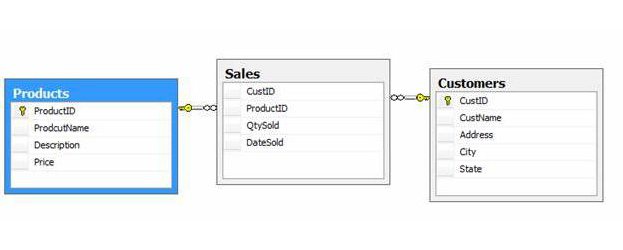
- एक "अनेक-अनेक" संबंध तब बनता है जब एक इकाई की कई पंक्तियों में दूसरी तालिका में कई रिकॉर्ड के साथ एक स्पष्ट तार्किक बातचीत होती है।
- अगर दो संस्थाओं के बीच हैसंयोजन "एक से एक", जिसका अर्थ है कि एक तालिका का मुख्य पहचानकर्ता दूसरी इकाई में मौजूद है, तो तालिकाओं में से एक को हटा दिया जाना चाहिए, यह अनावश्यक है। लेकिन कभी-कभी, विशुद्ध रूप से सुरक्षा कारणों से, प्रोग्रामर जानबूझकर दो संस्थाओं को अलग कर देते हैं। इसलिए, काल्पनिक रूप से, एक-से-एक संबंध मौजूद हो सकता है।
एक रिलेशनल डेटाबेस में चाबियों का अस्तित्व
प्राथमिक और द्वितीयक कुंजियाँ परिभाषित करती हैंसंभावित डेटाबेस संबंध। डेटा मॉडल के संबंधपरक लिंक में केवल एक संभावित कुंजी हो सकती है, यह प्राथमिक कुंजी होगी। वह किस तरह का है? प्राथमिक कुंजी एक इकाई स्तंभ या विशेषताओं का समूह है जिसके माध्यम से आप किसी विशेष पंक्ति के डेटा तक पहुंच सकते हैं। यह अद्वितीय, अद्वितीय होना चाहिए, और इसके क्षेत्रों में खाली मान नहीं हो सकते। यदि प्राथमिक कुंजी में केवल एक विशेषता होती है, तो इसे सरल कहा जाता है, अन्यथा यह एक घटक होगा।
प्राथमिक कुंजी के अलावा, एक बाहरी भी है(विदेशी कुंजी)। बहुतों को समझ में नहीं आता कि उनके बीच क्या अंतर है। आइए एक उदाहरण का उपयोग करके उनका अधिक विस्तार से विश्लेषण करें। तो, 2 टेबल हैं: "डीन का कार्यालय" और "छात्र"। "डीन के कार्यालय" इकाई में फ़ील्ड शामिल हैं: "छात्र आईडी", "पूरा नाम" और "समूह"। "छात्र" तालिका में "नाम", "समूह" और "औसत" जैसे विशेषता मान हैं। चूंकि छात्र आईडी एकाधिक छात्रों के लिए समान नहीं हो सकता है, इसलिए यह फ़ील्ड प्राथमिक कुंजी होगी। "छात्र" तालिका से "पूरा नाम" और "समूह" कई लोगों के लिए समान हो सकते हैं, वे "डीन के कार्यालय" इकाई से छात्र आईडी नंबर का उल्लेख करते हैं, इसलिए उन्हें एक विदेशी कुंजी के रूप में उपयोग किया जा सकता है।
संबंधपरक डेटाबेस मॉडल उदाहरण
स्पष्टता के लिए, हम दो संस्थाओं से मिलकर एक रिलेशनल डेटाबेस मॉडल का एक सरल उदाहरण देंगे। "डीनरी" नामक एक टेबल है।
सार "डीनरी" | ||
छात्र आईडी | पूरा नाम | समूह |
111 | इवानोव ओलेग पेट्रोविच | IN-41 |
222 | इल्या लाज़रेव | IN-72 |
333 | कोनोपलेव पेट्र वासिलिविच | IN-41 |
444 | कुश्नेरेवा नतालिया इगोरवाना | IN-72 |
पाने के लिए आपको कनेक्शन बनाने की आवश्यकता हैपूर्ण विकसित संबंधपरक डेटाबेस। रिकॉर्ड "IN-41", जैसे "IN-72", "डीन के कार्यालय" प्लेट में एक से अधिक बार मौजूद हो सकता है, और दुर्लभ मामलों में छात्रों का उपनाम, पहला नाम और संरक्षक मेल खा सकते हैं, इसलिए ये फ़ील्ड नहीं हो सकते हैं प्राथमिक कुंजी बनाई। आइए इकाई "छात्र" दिखाएं।
"छात्र" तालिका | |||
पूरा नाम | समूह | औसत अंक | फ़ोन |
इवानोव ओलेग पेट्रोविच | IN-41 | 3,0 | 2-27-36 |
इल्या लाज़रेव | IN-72 | 3,8 | 2-36-82 |
कोनोपलेव पेट्र वासिलिविच | IN-41 | 3,9 | 2-54-78 |
कुश्नेरेवा नतालिया इगोरवाना | IN-72 | 4,7 | 2-65-25 |
जैसा कि हम देख सकते हैं, रिलेशनल डेटाबेस में फ़ील्ड्स के प्रकारपूरी तरह से अलग। डिजिटल और प्रतीकात्मक दोनों प्रविष्टियां हैं। इसलिए, विशेषता सेटिंग्स में पूर्णांक, चार, वाचर, दिनांक और अन्य के मान निर्दिष्ट किए जाने चाहिए। "डीन के कार्यालय" तालिका में, केवल छात्र आईडी एक अद्वितीय मूल्य है। इस क्षेत्र को प्राथमिक कुंजी के रूप में लिया जा सकता है। "छात्र" इकाई से पूरा नाम, समूह और फोन नंबर छात्र आईडी के संदर्भ में एक विदेशी कुंजी के रूप में लिया जा सकता है। कनेक्शन स्थापित किया गया है। यह एक-से-एक संबंध मॉडल का एक उदाहरण है। हाइपोथेटिक रूप से, तालिकाओं में से एक अनावश्यक है, उन्हें आसानी से एक इकाई में जोड़ा जा सकता है। छात्र आईडी नंबरों को आम तौर पर ज्ञात होने से रोकने के लिए, दो तालिकाओं का अस्तित्व काफी यथार्थवादी है।








