Comment apprendre à un ordinateur à comprendre ce qui est représenté surimage ou photographie? Cela nous semble simple, mais pour un ordinateur, il ne s'agit que d'une matrice de zéros et de uns, à partir de laquelle vous devez extraire des informations importantes.

Qu'est-ce que la vision par ordinateur? C'est la capacité de l'ordinateur à "voir"
La vision est une source d'information importante pourpersonne, avec son aide, nous recevons, selon diverses sources, de 70 à 90% de toutes les informations. Et, bien sûr, si nous voulons créer une voiture intelligente, nous devons mettre en œuvre les mêmes compétences dans un ordinateur.
La tâche de vision par ordinateur peut êtren'est pas clairement formulé. Qu'est-ce que "voir"? C'est comprendre ce qui est où, rien qu'en regardant. C'est la différence entre la vision par ordinateur et la vision humaine. La vision pour nous est une source de connaissances sur le monde, ainsi qu'une source d'informations métriques, c'est-à-dire la capacité de comprendre les distances et les dimensions.
Noyau sémantique de l'image
En regardant l'image, on peut la caractériser par un certain nombre de fonctionnalités, pour ainsi dire, extraire des informations sémantiques.

Par exemple, en regardant cette photo, nous pouvonsdis que c'est à l'extérieur. Que c'est une ville, du trafic. Qu'il y a des voitures ici. De la configuration du bâtiment et des hiéroglyphes, on peut deviner qu'il s'agit de l'Asie du Sud-Est. D'après le portrait de Mao Zedong, nous comprenons qu'il s'agit de Pékin, et si quelqu'un a vu les émissions vidéo ou y a été lui-même, il peut deviner qu'il s'agit de la célèbre place Tiananmen.
Que pouvons-nous dire d'autre sur l'image en regardantsa? Nous pouvons mettre en évidence des objets dans l'image, par exemple, il y a des gens là-bas, voici plus près - une clôture. Voici les parapluies, voici le bâtiment, voici les affiches. Voici des exemples de classes d'objets très importantes actuellement recherchées.
Nous pouvons également extraire certains signes ou attributs d'objets. Par exemple, ici, nous pouvons déterminer qu'il ne s'agit pas d'un portrait d'un chinois ordinaire, à savoir Mao Zedong.
Vous pouvez dire par la voiture que c'estun objet en mouvement, et il est rigide, c'est-à-dire qu'il ne se déforme pas pendant le mouvement. On peut dire à propos des drapeaux que ce sont des objets, ils bougent aussi, mais ils ne sont pas rigides, ils sont constamment déformés. Et il y a aussi du vent dans la scène, cela peut être déterminé par le drapeau flottant, et vous pouvez même déterminer la direction du vent, par exemple, il souffle de gauche à droite.
La valeur des distances et des longueurs en vision par ordinateur
Les informations métriques sont très importantes dans la science de la vision par ordinateur. Ce sont toutes sortes de distances. Par exemple, pour un rover, cela est particulièrement important, car les commandes depuis la Terre prennent environ 20 minutes et la réponse est la même. En conséquence, la connexion aller-retour dure 40 minutes. Et si nous élaborons un plan de mouvement selon les ordres de la Terre, alors cela doit être pris en compte.

Technologie de vision par ordinateur réussieintégré aux jeux vidéo. À partir de la vidéo, vous pouvez créer des modèles tridimensionnels d'objets, de personnes et à partir de photos d'utilisateurs, vous pouvez restaurer des modèles tridimensionnels de villes. Et puis marchez le long d'eux.
Vision par ordinateur Est une zone assez large. Il est étroitement lié à diverses autres sciences. Vision par ordinateur partielle capture le domaine du traitement d'image et met parfois en évidence le domaine de la vision industrielle, historiquement, cela s'est produit.
Analyse, reconnaissance de formes - le moyen de créer un esprit supérieur
Analysons ces concepts séparément.

Le traitement d'image est un domaine d'algorithmes où l'entrée et la sortie sont une image, et nous faisons déjà quelque chose avec.
L'analyse d'image est un domaine de la vision par ordinateur qui se concentre sur le travail avec une image bidimensionnelle et en tire des conclusions.
La reconnaissance de formes est abstraiteune discipline mathématique qui reconnaît les données comme des vecteurs. Autrement dit, il y a un vecteur à l'entrée et nous devons faire quelque chose avec. D'où vient ce vecteur, il n'est pas si important pour nous de savoir.
La vision par ordinateur était à l'originereconstruction de la structure à partir d'images bidimensionnelles. Maintenant, cette zone est devenue plus large et elle peut être interprétée en général comme la prise de décisions sur des objets physiques en fonction de l'image. Autrement dit, c'est la tâche de l'intelligence artificielle.
Parallèlement à la vision par ordinateur, dans un tout autre domaine, en géodésie, la photogrammétrie s'est développée - c'est la mesure des distances entre objets à l'aide d'images bidimensionnelles.
Les robots peuvent "voir"
Et le dernier est la vision industrielle. La vision industrielle fait référence à la vision des robots. Autrement dit, la solution de certains problèmes de production. On peut dire que la vision par ordinateur - c'est une grande science. Il combine en partie d'autres sciences. Et lorsque la vision par ordinateur reçoit une application spécifique, elle se transforme en vision industrielle.

Le champ de la vision par ordinateur a une masseApplications pratiques. Il est associé à l'automatisation de la production. Dans les entreprises, il est de plus en plus efficace de remplacer le travail manuel par du travail mécanique. La machine ne se fatigue pas, ne dort pas, son horaire de travail est irrégulier, elle est prête à travailler 365 jours par an. Ainsi, en utilisant le travail de la machine, nous pouvons obtenir un résultat garanti à un certain moment, ce qui est assez intéressant. Toutes les tâches des systèmes de vision par ordinateur ont une application visuelle. Et il n'y a rien de mieux que de voir le résultat directement sur l'image, uniquement au stade des calculs.
Aux portes du monde de l'intelligence artificielle
De plus, la zone est difficile! Une partie essentielle du cerveau est responsable de la vision, et on pense que si vous apprenez à un ordinateur à "voir", c'est-à-dire à appliquer pleinement la vision par ordinateur, alors c'est l'une des tâches complètes de l'intelligence artificielle. Si nous pouvons résoudre le problème au niveau humain, nous résoudrons très probablement le problème de l'IA en même temps. Ce qui est très bien! Ou pas très bien si vous regardez Terminator 2.
Pourquoi la vision est-elle difficile? Parce que l'image des mêmes objets peut varier considérablement en fonction de facteurs externes. Les objets ont une apparence différente selon les points d'observation.
Par exemple, une seule et même figure tirée de différentsangles. Et ce qui est le plus intéressant, une silhouette peut avoir un œil, deux yeux ou un œil et demi. Et selon le contexte (s'il s'agit d'une photo d'une personne portant un T-shirt aux yeux dessinés), il peut y avoir plus de deux yeux.
L'ordinateur ne comprend pas encore, mais "voit" déjà
Un autre facteur qui crée des difficultés estéclairage. La même scène avec un éclairage différent sera différente. La taille des objets peut varier. De plus, les objets de n'importe quelle classe. Eh bien, comment pouvez-vous dire à propos d'une personne que sa taille est de 2 mètres? En aucune façon. La taille d'une personne peut être à la fois de 2,3 m et 80 cm. Comme les objets d'autres types, ce sont néanmoins des objets de la même classe.

Les objets vivants en particulier subissent le plusdiverses déformations. Cheveux de personnes, d'athlètes, d'animaux. Regardez des photos de chevaux qui courent, il est tout simplement impossible de déterminer ce qui se passe avec leur crinière et leur queue. Qu'en est-il des objets qui se chevauchent dans l'image? Si vous glissez une telle image dans un ordinateur, même la machine la plus puissante aura du mal à donner la bonne solution.

Le type suivant est le déguisement. Certains objets, animaux se déguisent en environnement, et assez habilement. Et les taches sont les mêmes et les couleurs. Néanmoins, nous les voyons, mais pas toujours de loin.
Un autre problème est le mouvement. Les objets en mouvement subissent des déformations inimaginables.
De nombreux objets sont très variables. Par exemple, dans les deux photos ci-dessous, il y a des objets de type "chaise".

Et vous pouvez vous asseoir là-dessus. Mais apprendre à une voiture que des choses aussi différentes en forme, en couleur, en matériau sont tous des objets de la «chaise» - c'est très difficile. Telle est la tâche. Intégrer les méthodes de vision par ordinateur, c'est apprendre à une machine à comprendre, analyser, assumer.

Intégration de la vision par ordinateur dans diverses plateformes
La vision par ordinateur a commencé à pénétrer les masses mêmeen 2001, lors de la création des premiers détecteurs de visage. Cela a été fait par deux auteurs: Viola, Jones. C'était le premier algorithme rapide et raisonnablement fiable à démontrer la puissance des méthodes d'apprentissage automatique.
Maintenant, la vision par ordinateur a une application pratique assez nouvelle - la reconnaissance faciale.
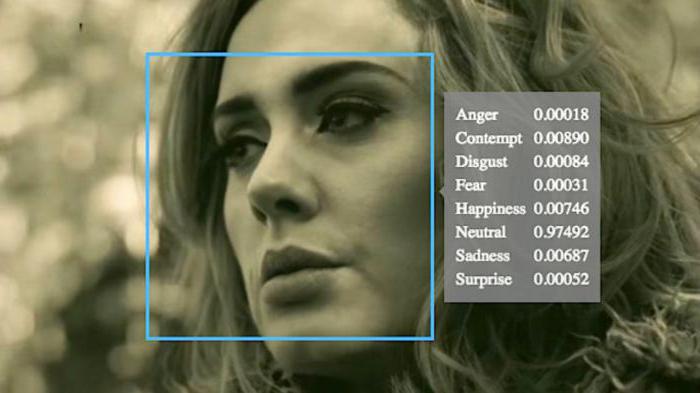
Mais pour reconnaître une personne, comme le montrefilms - sous des angles arbitraires, avec des conditions d'éclairage différentes - est impossible. Mais pour résoudre le problème, que ce soit une ou plusieurs personnes avec un éclairage différent ou dans des positions différentes, similaires, comme sur la photo du passeport, vous pouvez avec un haut degré de confiance.
Les exigences relatives aux photographies de passeport sont en grande partie dues à la particularité des algorithmes de reconnaissance faciale.
Par exemple, si vous avez un passeport biométrique, dans certains aéroports modernes, vous pouvez utiliser le système de contrôle automatique des passeports.
Un problème non résolu en vision par ordinateur est la capacité de reconnaître un texte arbitraire
Quelqu'un a peut-être utilisé le systèmereconnaissance de texte. L'un d'eux est Fine Reader, un système très populaire sur Internet russe. Il existe de nombreux formulaires où vous devez remplir des données, ils sont parfaitement scannés, les informations sont très bien reconnues par le système. Mais avec du texte libre sur l'image, la situation est bien pire. Cette tâche n'est toujours pas résolue.
Jeux impliquant la vision par ordinateur, la capture de mouvement
Un grand espace séparé est la créationModèles 3D et capture de mouvement (qui est implémenté avec succès dans les jeux informatiques). Le premier programme qui utilise la vision par ordinateur est un système d'interaction avec un ordinateur à l'aide de gestes. Lors de sa création, beaucoup de choses ont été découvertes.
L'algorithme lui-même est assez simple, mais pour celapersonnalisation nécessaire pour créer un générateur d'images artificielles de personnes pour obtenir un million d'images. Le supercalculateur les a utilisés pour sélectionner les paramètres de l'algorithme, selon lesquels il fonctionne désormais de la meilleure façon.
C'est un million d'images et une semaine à compterle temps du superordinateur a permis de créer un algorithme qui consomme 12% de la puissance d'un processeur et vous permet de percevoir la posture d'une personne en temps réel. Il s'agit du système Microsoft Kinect (2010).

La recherche d'images par contenu vous permet de télécharger une photo sur le système et, par conséquent, elle renverra toutes les images avec le même contenu et prises sous le même angle.
Exemples de vision par ordinateur: des cartes 3D et 2D sont désormais réalisées à partir de celle-ci. Les cartes pour les navigateurs de voiture sont régulièrement mises à jour en fonction des données des DVR.
Il existe une base de données avec des milliards de photos degéomarques. En téléchargeant une photo dans cette base de données, vous pouvez déterminer où elle a été prise et même sous quel angle. Naturellement, à condition que l'endroit soit assez populaire, qu'à un moment donné les touristes l'ont visité et ont pris un certain nombre de photographies de la région.
Les robots sont partout
La robotique est partout aujourd'hui, sans elleen aucune façon. Maintenant, il existe des voitures qui ont des caméras spéciales qui reconnaissent les piétons et les panneaux de signalisation afin d'envoyer des commandes au conducteur (en un sens, un programme informatique pour la vision qui aide le passionné de voiture). Et il existe des voitures robotisées entièrement automatisées, mais elles ne peuvent pas compter uniquement sur un système de caméra vidéo sans utiliser beaucoup d'informations supplémentaires.
Un appareil photo moderne est un analogue d'un appareil photo à sténopé
Parlons d'imagerie numérique. Les appareils photo numériques modernes sont conçus comme un appareil photo à sténopé. Seulement au lieu d'un trou à travers lequel un rayon de lumière pénètre et projette le contour d'un objet sur la paroi arrière de la caméra, nous avons un système optique spécial appelé lentille. Sa tâche est de collecter un grand faisceau de lumière et de le transformer pour que tous les rayons passent par un point virtuel afin d'obtenir une projection et de former une image sur un film ou une matrice.

Appareils photo numériques modernes (matrice)se composent d'éléments individuels - pixels. Chaque pixel vous permet de mesurer l'énergie de la lumière qui tombe sur ce pixel au total, et en sortie de donner un nombre. Par conséquent, dans un appareil photo numérique, au lieu d'une image, nous recevons un ensemble de mesures de la luminosité de la lumière qui est tombée dans un pixel séparé - les champs de vision de l'ordinateur. Par conséquent, lorsque l'image est agrandie, nous ne voyons pas des lignes lisses et des contours clairs, mais une grille de carrés peints dans des tons différents - des pixels.
Voici la première image numérique au monde.
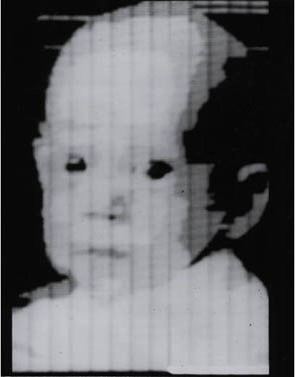
Mais que manque-t-il à cette image? Couleur. Qu'est-ce que la couleur?
Perception psychologique de la couleur
La couleur est ce que nous voyons. La couleur d'un objet, le même objet pour une personne et un chat sera différent. Puisque nous (les humains) et les animaux, le système optique - vision, est différent. Par conséquent, la couleur est une propriété psychologique de notre vision qui se produit lors de l'observation d'objets et de lumière. Pas une propriété physique d'un objet et de la lumière. La couleur est le résultat de l'interaction des composants de la lumière, de la scène et de notre système visuel.

Programmation de vision par ordinateur en Python avec des bibliothèques
Si vous décidez d'étudier sérieusementvision par ordinateur, vous devez immédiatement vous préparer à un certain nombre de difficultés, cette science n'est pas la plus facile et cache un certain nombre de pièges. Mais Computer Vision Programming in Python par Jan Erik Solem est un livre qui présente tout de la manière la plus simple possible. Ici, vous vous familiariserez avec les méthodes de reconnaissance de divers objets en 3D, apprendrez à travailler avec des images stéréo, la réalité virtuelle et de nombreuses autres applications de vision par ordinateur. Il y a suffisamment d'exemples en Python dans le livre. Mais les explications sont présentées, pour ainsi dire, de manière généralisée, afin de ne pas surcharger d'informations trop scientifiques et difficiles. Le travail convient aux étudiants, juste aux amateurs et aux passionnés. Vous pouvez télécharger ce livre et d'autres sur la vision par ordinateur (format pdf) en ligne.
En ce moment, il y a une bibliothèque ouvertealgorithmes de vision par ordinateur, ainsi que traitement d'images et algorithmes numériques OpenCV. Il est implémenté dans la plupart des langages de programmation modernes et est open source. Si nous parlons de vision par ordinateur, en utilisant Python comme langage de programmation, alors il a également le support de cette bibliothèque, en plus, il est en constante évolution et a une grande communauté.
Microsoft fournit sesServices d'API qui peuvent entraîner les réseaux de neurones à travailler avec des images faciales. Il est également possible d'utiliser la vision par ordinateur, en utilisant Python comme langage de programmation.





